hi all, have been working on some other ideas re A(G)I, heavily promoting them all over cyberspace + analyzing/ collecting copious references, and havent been banging on collatz quite as much last few weeks. honestly its a bit of a (well deserved) break or respite. however, its always at the back of my mind. feel that am getting close to a solution but theres a lot of trickiness/ subtlety in the current stage.
here is a new analogy/ pov. the linear regression is finding a “global/ local gradient”. for the theoretical trajectory it is both, for the actual trajectory there are local perturbations/ disturbances/ noise fluctuations in the global trend. the picture is something like the wind blowing a leaf. the leaf has a very definite position but does a sort of multi-dimensional (3d) random walk in the wind. the wind is a general trend. now the basic idea/ question is whether the leaf will land at a given location/ circumscribed area given a predictable/ consistent wind dynamic.
further thought, another way of looking at it is that the leaf has a very dynamic/ even sharp response to the wind depending on what its current orientation is, and it also has an internal momentum. actually since the (real) wind is typically so dynamic whereas the linear regression is fixed (although arriving at the final regressions was dynamic, cf earlier saga of that), one might instead use the similar analogy of an irregularly shaped object in a (more consistent/ uniform) fluid flow, maybe even a field.
have been pondering the “gradient descent” analogy. its a very helpful/ fruitful analogy that has served for a lot of analysis/ advance. but— “low hanging fruit”? heres a key consideration. Newtons method does not exactly involve gradient descent! if one is solving the equation 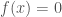
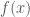
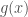

so need to think/ meditate more on gradient descent vs Newtons method wrt this problem! have been missing some of the fundamental interconnection in all the prior work.
another rather gaping problem with the gradient descent area is that so far it still isnt very clear at all exactly what function/ gradient is being “descended”/ undergoing descent. a few months ago, thought it wouldnt be hard to figure out at all, but its turning out to be quite challenging/ difficult at this point. on other hand feel there is maybe a simple solution that is eluding me.*
💡 now, had another really great idea. the eigenvalue decomposition is very similar to the SVD, singular value decomposition. its nearly the same concept except SVD is more general and can be applied to rectangular instead of only square matrices. but what is interesting about SVD is that it has a remarkable interpretation eg that can be found with ratings systems or search engines, in the technology called “LSA/ LSI” or “latent semantic analysis/ indexing”. (there also seems some analogy to spectral analysis theory of graphs.)
in these systems, there is a concept of feature vectors. an arbitrary “data vector” (eg a customer rating or a document vector etc) is decomposed as a linear combination of feature vectors. the feature vectors are analogous to eigenvectors!
the matrix multiplication recurrence relation has an uncanny similarity to this theory. it looks like the recurrence relation is basically a process of “growing feature vectors”. and the eigenvalues are the linear “size/ scale” of the feature vectors.
in other words the SVD theory derives a transformation/ mapping from the raw data to “feature space” where it is more effectively/ meaningfully analyzed.
am not sure about this but suspect that the eigenvector matrix and its inverse can also be interpreted as rotations in n-dimensional space. need to refamiliarize myself with this and suspect this interpretation is not exactly widely understood, because many accounts of eigenvalue decomposition have no reference to it.
💡 now, this leads to what (a priori) seems to be another really great idea. suspect that it will be quite natural to decompose real collatz trajectories onto the linear combination of feature vectors for better analysis! and then need to understand the scaling dynamics involved.
and actually this all seems to be highly interrelated with last installments ideas on finding something like the matrix exponentiation (times initial vector) inverse/ root function. am thinking the underlying math maybe is not all that different than what has already been laid out, but its an entirely new pov that seems to be promising/ expansive.
* ⭐ 💡 ❗ further quick thought. another idea in the back of my mind. the model gives a (apparently nonanalytic ie not a mere formula) estimate for glide distance. maybe that is the basic gradient descent long being sought! the natural question is, how noisy is this estimate? the estimate is naturally/ by design roughly monotonic. can this “rough monotonicity” be strengthened somehow to “strictly monotonic”? as has long been pointed out in these blogs, that is equivalent to a proof. note also the old idea applicable here of looking for bounds on “maximum nonmonotonic run length”… (a constant bound would be fantastic but any provable “O(f(n))” bound would possibly be sufficient…) so that quantifies it in one sense, and also a adversarial algorithm attempting to break it is another looming idea/ question/ experiment!
⭐ ⭐ ⭐
(2/2) this is some fairly simple code to investigate some of these angles. consider a glide as separated/ split between a “climb” and a “fall” on the two sides of its maximum. this generates 100 trajectories and sorts them by difference between max (bit) width and starting bit width, and then applies the model to estimate “remaining distance” over all the iterates in the 10 top climbs. remaining distance is different than glide length because (as noted in other contexts) as an iterate “climbs” its new glide distance is shorter.
however, as seen here even “remaining distance” has some subtlety remaining. green line is the bit width, red line is the model remaining distance estimate. note, (admittedly counterintuitively) trajectories are in reverse order so that “remaining distance” increases left-to-right. the 3rd line is quite evocative in showing that the model is more estimating the “proportion of (vertical) climb remaining” than “distance to maximum (in horizontal iterations)” because as the glide hovers at a plateau around/ yet right below the maximum, the estimate is low/ flatlines. and this shows the likely ineffectuality of using the max nonmonotone run length which would be high in this case. also there is quite a bit of noise as the estimate noisily/ intermittently plunges to baseline.
alas, all this does seem to throw some wrench in the works because the model estimate is far from monotonic and dont see an immediately obvious way to increase its monotonicity. have long/ almost always been focused on a proof in terms of trajectory “horizontal distance” but this model seems to estimate “vertical distance”.
one hope: (theres that old standby that…) maybe a small finite set of iterates can be excluded from the model, or some “small” constant # of final (climb) iterations (possibly wrt an iterate bit width limit) etc. although maybe the 2nd idea is already ruled out by case #3 which would seem to require at least ~50 iterations excluded. (but whether 50 is “small” is a question of computational relativity!) oh and the other wrench in the works is that the iterates to be excluded are larger at ~110 than the rest of the sequence in the 3rd case— so the lower bound would be applied to the model prediction instead of the sequence— ie also have to be careful about overall thinking of the climb vs the glide, and this reverse ordering in the graph of the trajectory is not helping either!
❓ but again the interminable/ so far unanswerable key/ core/ central zen question rears its head… how good does the estimator have to be to lead to a proof? and closely related, how does one convert an apparently consistent formula into a proof?

💡 ⭐ ❓ an analogy that has been occurring to me lately, long at the back of my mind. call it “process of inversion”. in algebra there is an idea of solving an equation for a variable by manipulating different sides of the equalities and via substitution. it would seem there is a process of isolating a variable in which all the operations surrounding it are piece-by-piece inverted. now, during this collatz saga, have been aware of something that seems similar. it seems as if one is trying to convert undecidable operations into decidable ones via piece-by-piece inversions (notice the above graph again, which is basically creating a new function “distance remaining” that is roughly inverting the trend of the trajectory), incrementally decreasing the undecidable side and incrementing the decidable side so to speak. ie another sense— “chewing off and digesting”. this picture/ pov keeps tugging at my thinking (aka haunting) but still cant quite nail it down exactly. its a small )( glimmer of the more general theory (long) being sought. and interestingly it also seems to relate to machine learning systems that build up their model structures over time. another common theme is decreasing error/ uncertainty in the multiple senses of the words.
(2/5) 💡 ❗ ⭐ still thinking! trying to remember. was the idea of entropy discussed wrt the problem in a past blog? my current AGI (side) focus reminds me of this angle. it appears that somehow the operations of the proof attempt go in the direction of decreasing entropy in the calculation. it seems a possibly nonterminating TM has maximal entropy. or maybe there are TMs that both halt and dont halt with very “ordered” calculations, and sandwiched in between are very disordered, high entropy computations (aka what are known as “tableaus”) and the ultimate goal is to convert disordered tableaus to ordered ones!
another angle/ pov: again it looks like the goal is to determine a “general loop invariant”. doing so appears to involve generally attempting to calculate either the max of a glide or distance to max using “local” statistics (the local vs global dichotomy). the local calculations are bounded, the global ones are potentially unbounded or “indeterminate/ TBD/ unknown”. decreasing the noise of the predictor also apparently correspondingly involves bounding the unknown/ “remaining part” (of the global property/ ie termination). the above/ prior estimate of distance-to-max is not terrible, but noisy. so theres major effort in decreasing the noise of the estimator, which involves “increasing its monotonicity”. there is a point where even with noisy nonmonotonicity, that can be averaged/ smoothed out or evaded with the nonmonotone run length metric method (actually the 2 are surely closely related… noise associated with/ related to n-iteration averaging is likely closely linked to n-iteration nonmonotone run lengths). ie a basic guiding principle related to the algebraic operations/ inversions/ entropy-reduction idea, not unlike machine learning itself:
noisy → smooth
(2/7) another idea. it would seem that the goal is to estimate the trajectory peak within some constant bound of error from some finite # of initial iterates or metrics on those iterates. but this seems rather implausible for very large starting iterates. but then was thinking, maybe have something of a mental block here. maybe the estimate can include any bounded amount of initial iterates. the simplest bound is ofc a constant, but another type of bound seems natural given prior experiments. it looks like the trajectory length might be (roughly!?) bounded by a constant × # of bits in the starting iterate. maybe using metrics on a constant × initial bit width bound of initial iterates is plausible/ viable. is this enough to get a very good estimate within a constant bound of the trajectory peak? or maybe a constant multiple? etc…
or more formally, something like this. f(x) is some bound of initial iterate x and the estimate calculates f(x) starting iterates and (finite!) metrics thereof. then it (provably?) estimates peak distance within some error bound g(x). there is a sense that accurately estimating peak distance within some (bounded!) error apparently inverts the function such that one can compute a monotonic (declining) function from it. need to sketch all that out better.
also the prior code to estimate trajectory length (via matrix multiplication recurrence) is quite interesting in following way. it appears to be a highly nonlinear formula or calculation but yet apparently (from all the prior analysis) consistently terminating. in fact in the proof construction one is very interested in all functions that provably terminate but maybe not using simple math formulas/ proofs. what is the structure of those functions, how can they be built up? machine learning function generation seems to be one close metaphor. as my other A(G)I research tracks, its an increasingly large “universe” every day…
(2/9) have some semiambitious ideas that am building on (working toward an averaging idea and analysis over multiple matrix parameters etc) but this is an intermediate point that had some unusual finding(s). this new version on prior one creates a loop around the distribution generation to find more samples/ eliminating duplicates, and has better graph generation logic, eg splitting the separate trajectories by some visual gaps, and reverse trajectory order from prior one to normal ordering which is judged less confusing. it analyzes trajectories with climbs longer than 25 count.
however started to notice quite interesting trajectories popping up in these plots. what is very notable is trajectory #4 a sort of “sawtooth squiggle”. also #9 is striking, a sort of “filled squiggle”. note in both cases the corresponding distance estimates are fairly high quality! saw another one wish could have saved, it was something like (in words) “double bump theme repeated”! do not recall having seen anything like this before. leading to some question like what is going on here? the long observed/ commented fractal nature of the problem continues to rear its head in surprising/ unexpected ways.
ofc the nearly linear climbs are also quite notable but suspect there may be simple explanations for those. ideally every piece of code written would have a mechanism to save unusual trajectories but need to add it to this code to capture these. thankfully it looks like theyre not to rarely encountered in this generation process and can replicate them.
trajectory #2 is also notable because its again the same hurdle that needs to be overcome, its a long trailing flat estimation plateau that is an the obstacle to (smooth/ consistent) monotonicity.

⭐ ⭐ ⭐
❗ 😮 ⭐ ❓ 😀 😎 😳 🙄 ❤ holy cow! its a bit of a detour to go looking at individual trajectories at this point but theres always some kind of diversion/ distraction/ tangent to go on with this problem. decided to go look at those “squiggly” trajectories and was not disappointed, am in fact utterly stunned with the eyepopping results, and feel the following results add an almost entirely new dimension to the analysis (how could this possibly be missed until now?). the old technique/ trick of looking at the bit patterns turned out to be momentous in this case also. my feeble excuse for missing it is that maybe/ it seems somehow these trajectories are “atypical”.
the prior code was modified slightly to output the trajectory starting values. then these were “harvested” based on visual analysis/ screening for the “squiggly” trajectories. then these were analyzed with new code that simply hardcodes the selected ones in an array and displays the bit widths in green and binary structure in red. note lsbs are nearest to origin.
got slightly carried away with all the amazement and captured 5 x 5 twenty five separate graphs in fairly short time. there is so much to say, so many impressions, its an embarrassment of riches, am overwhelmed, am going to add it after the graphs instead of before this time!





- triangles! fractal self similarity!
- maybe saw “smaller” triangles in some earlier experiments but didnt comment and/ or realize they could get so big!
- order vs disorder/ entropy/ noise!
- it seems almost that its a kind of wallpaper and the different trajectories are just capturing different cropping regions.
- the patterns are quite similar to those observed by Wolfram for various cellular automata. if there was any doubt about the connections of this problem to CAs, it would have to be erased on looking at these images.
- in fact its so striking one immediately wonders is there is a 1-d automata that corresponds to the collatz function? wouldnt it be stunning if one existed? defn suspect that a “highly local” CA does exist and old work on the collatz transducer (which works in a bit-serial fashion) would tend to support/ maybe almost directly confirm that idea… maybe even if not immediate/ direct some “small”/ “simple” transformation makes it work?
- the importance of (bit/ binary) density and its relation to different bit areas/ regions of the iterates becomes apparent. the solid density vs scattered density regimes are quite distinct. it also shows the evolution of density within regions.
- also quite similarly, one of the current metrics measured is “bit run length” for both empty/ filled bits, and its significance in the data is quite obvious now. also it shows visually at a glance why there is an asymmetry/ difference between 0-bit statistics and 1-bit statistics.
- the last trajectory is linear increasing, followed by a squiggly gradual decline, followed by a linear increase. notice that the triangular regions show up on the left/ right end inclines but not the sandwiched decline. although the left patterns are more like diagonal offset/ 45 degree rotated square edges than triangles.
- there are some white “empty” triangles (“anti-triangles”?) apparent in some of the plots. eg plot #2 instance #4 top, plot #2 instance #2 lower.
- the scattered horizontal and vertical line are a moire-like pattern due to not normalizing pixel horizontal/ vertical sizes.
- it seems not impossible that some of the same ranges are captured in these plots, but careful analysis would have to be done. its very tempting to try to analyze regions for similarity but that would be time consuming.
- note each pattern/ trajectory is strictly normalized in that peak is at the end of each. that should rule out some possibility of exact repetitions in different cases/ instances.
- the density shift is an unmistakable trend/ “evolution” from higher order/ solid density to disorder/ scattered.
- it makes one wonder if glides and presence of triangles are somehow related…?
- converted to binary many of the msds are nearly identical. seems like there ought to be some simple explanation but honestly cant explain that right now!
- there seems to be three basic density regimes/ region tendencies, apparently something like strange attractors: solid, empty (both typically triangular), and scattered.
- for a long time have been optimizing trajectories by various critiera and some led to starting seeds with characteristic properties such as with high bit sparsity. in light of this those trajectories ought to be reexamined for patterns! possibly have been treating it all too much like a black box previously.
- bit width linear increase trends showed very similar patterns. need to do a collection on those asap! (here it is!)
instead of posting the code am just gonna list the starting trajectory #s that can be substituted into the last code.
the density of the scattered region in the middle graph seems lower than the other two graphs, but think this is a trick again of the nonstandard pixel sizes; that graph has less horizontal compression than the other two. the 45 degree angle phenomenon in “middle” solid regions is typical here.
the similarity of the runs seems quite apparent in these last 3 graphs, the graph instances seem to contain similar themes. it appears to be some kind of bias in the random number generation it seems. or maybe (more likely?) its a trick of the eye due to the horizontal pixel compression. oh but wait, there seems to be some correlation in the base 10 msds of the sets…!?)
u = [1267650600228229401496703205375, 1267630047899000142442027548671, 1267650600228226868221912809471, 1267650600228229401496703205375, 950737799055444599293880565759, 1267650222438908520125272424447, 1109188230570602090213788352511, 1267648182376590101869609615359, 1265174115686460594460072869887, 1267631252683525677339035828223, 1255271162056443735790550253567, 1257747079323650548938804559871, 1099290753335882174719565234175, 1247843484039412683381487435775, 950737949580876240763821752319 ]



finally, after the detour, heres the “more ambitious” idea that was working towards. this uses large starting seeds with 500 bit width, limits to climbs of at least 50 iterations, serially averages/ smooths out the estimator over 20 points, and graphs the (max/ worst case) nonmonotone run length over 10 runs. (looked through 2017 blogs and did not find any nonmonotone run length code & wonder if it was used that year at all!) the results are roughly already as noted, maybe predictable, and yet still somewhat disappointing. there are long nonmonotone run lengths even in the 20-point averaged/ smoothed curves for all the 27 models generated of around ~100 iteration lengths. heres graphs for 2 different models with averaged signal in red, left side scale, and bit width green, right side scale.
at this point my next idea is maybe to look at some kind of function/ blending of multiple or all models esp wrt the worst (“hard”) cases, maybe leaning toward “most conservative possible” eg weighting those with the highest or least-decreasing estimate the most. the general failure is that the predictor goes very close to zero (flatlines) even as a “lot” of climb is left (clarification: typically horizontally via iterations, but not vertically). in a/ some sense it doesnt seem to have enough “resolution”. also am wondering if this is a symptom of iterates with “core density” losing predictive capability wrt the model based mainly on density metrics. ie some trajectories stay in the core for long periods of time, either falling, rising, or plateauing, with the metrics not able to discriminate between the cases? maybe they are more disordered/ random looking?
one positive observation is that it looks like all 27 models never diverge on any of the many trajectories seen so far. that would likely show up as spikes in the predictor/ estimator. ie even as the estimator is very nonlinear, its apparently very consistently nondivergent at least over metrics for real iterates. another very encouraging sign is that the estimator is very consistent over long runs either declining or flatlining even as the iterate is apparently shifting a lot over that span, ie predictor/ estimator seems to be definitely extracting some kind of signal.


(2/10) this took a lot of coding attn but is quite powerful/ revealing with major data crunching. it finds “hard” trajectory climbs by process of elimination. it starts with a sample of long climbs using the prior algorithms. then finds the best performing model out of 27 saved on the top 10 long climbs. finally it outputs nonmono run lengths and graphs results. if at the end a (relatively) long nonmono run length is reported it means that all 27 of the models were weak on that trajectory. the starting seeds are listed so that the prior analysis code unique could still be used to look at binary patterns.
the results are somewhat as predicted. even though there is some (hoped-for) variability/ (degree of) uncorrelation in the model predictions, they apparently tend to fail in a similar way. in this graph the 1st 3 longest trajectory nonmono run lengths are (moderate/ not bad!) 34, 26, 11. for record the starting seeds are 1223084758813955711600334733311, 1106718394936662525022721540095, 1107956335160415346034716180479. the graph includes density of iterate in blue (right scale) and shows the models are generally flatlining in their predictions when density approaches the core. from examination, these core regions typically do not have the “structure” depicted in the prior analysis/ pictures. also the declining density is highly correlated with iterate size increase.
a slightly better analysis would depict/ indicate the max nonmono run length “section”/ span/ location but it seems to (as already noticed/ hinted/ nearly pointed out) typically show up in the estimator/ predictor plateaus. however bottom line is that it looks like the training bias might be showing through; all the past training samples for this overall model were based on density variation, and it looks like within core density there is a lot of variation in behavior not captured by the models and possibly arbitrarily long climbs or at least long plateaus can be hidden/ embedded there like the longtime observed “needle in haystack” tendency. and note anyway the “feature detectors” all generally related to density would be expected to “fall down” if there is some major variation in behavior within the core density.

(2/11) this code highlights the max nonmonotone run region with bottom solid spanning bars in gray. had to nearly completely refactor the nonmonotone run calculator code. maybe have never tracked the exact region with that code before, after spot checking thru all the old code! wanted to add in the code to visualize the binary structure but ran out of time at the moment. this code also sets the initial seed sizes back to 100 bits from 500. 100 bits is the size of training data. in a way its exceptional that the prior code works so well on 5x size seeds versus the training sizes. it also uses the convenient inline data file feature of gnuplot for the bars, possibly not used in any prior code so far. after some runs the max nonmono run length seems around ~50 count.

⭐ ⭐ ⭐
(2/12) 💡 ⭐ 🙄 😮 ❗ have some ideas maybe meshing towards a “grand synthesis”. am having that feeling of having gone “full circle”. after many months of analyzing density-related matrix difference equations, have now found they work well on iterates with some kind of major density variation (away from the core) but generally not so well inside it (near ½ density). and therefore, as already somewhat encountered/ discovered, some other mechanism for analyzing dynamics seems to be required on the “inside core” iterates. but then had a major paradigm shift/ inspiration in mind.
it looks like density is really a shorthand for order vs disorder. far-from-core (either low or high) density iterates are likely to have long bit runs! these runs are part of the “(anti-)triangles” and are more “ordered”. the progress of iterations is, somewhat shockingly, clearly from higher order to higher disorder…
in other words, a 2nd law of thermodynamics analogORDER → DISORDERhas been detected in the problem!
note that density is only a very rough estimator of disorder as the following contrived/ simple example shows. imagine two iterates, both at ½ density. one could have two huge (continuous) runs of 1s and 0s, the other could alternate 1s and 0s, and yet another could have them all (0s/ 1s bits) highly scattered. yet all are far different in their order vs disorder, at one (high) extreme of the spectrum to the other (low), resp! ie a “typical” ½-density iterate chosen at random would likely be disordered, but there are “many” ordered exceptions with long bit runs (again the “needles in the haystack” theme)!
so my new idea is to better focus on order vs disorder rather than “merely” density! ofc the two are interrelated but that interrelation needs to be better isolated/ analyzed/ understood! ie a ~½-density “continuous/ ordered” iterate apparently has to evolve into a ~½-density “broken/ scattered/ disordered” state. eg another metric to detect “inside scattered core” instead might be looking at max 0 and max 1 run lengths, and requiring that they be small, etc… another way of looking at this is that apparently a new crucial concept emerges of “0/1 bit mixing/ scatter”…
the new foremost/ primary question to answer: what kind of key constraints, bounds, limits are associated with/ can be applied to the scattered core? some older analysis maybe already gives a strong lead/ advance on this question… just reviewed old experiment that seemed to show limit on # of iterations in core ½-density crossovers! however another immediate observation from results/ inspection of last code here is that it looks there can be long gradual climbs in the scattered core of say at least ~50 iterations.
(2/13) 💡 ❗ ⭐ 😮 😎 😀 some of that intuition/ conjecture/ hypothesis is immediately confirmed! this code is loosely related to old optimization series extend last touched on last spring (may). the fairly simple idea is to limit the max 0/1 bit runs while searching for larger/ maximizing ‘c’ trajectory climb lengths. results were a bit startling and actually initially wondered if there was a defect because was starting with low limits (instead of higher in the final version) and wasnt finding any trajectories. there seems to be a very strong transition point. in this graph ‘m’ is the max run length limit. ‘mmx’ is the max run length encountered during the optimization (of the top trajectory). the two metrics are graphed left side scale, red/ green respectively. there are 4 runs per ~25 points evaluated serially. theres also some statistics cache logic.
the blue line is the resulting max climb found under the limit, right side scale. as seen it drops off dramatically at around ~7 max bit runs. the bottom line is that limiting bit run lengths seems also to strongly restrict any “climbing” (“potential”). while plausible and possibly a breakthru (for just previously sketched out reasons, and which the attentive/ astute reader will quickly grasp) this needs to be tested a bit more rigorously eg with a genetic algorithm. hint: after this, 0/1 run lengths are starting to look like a fractal aspect of the dynamics. and have been musing, its a new manifestation of the so called “painting into corner” effect that is possibly/ hopefully not an “artifact”…

(2/14) ❗ 😀 cranked out genetic algorithm version asap. results are nearly the same, showing the general reliability/ effectiveness/ efficiency of the prior bitwise optimization algorithm. the GA ran for a much longer ~30m or so. there seems to be maybe a little more variability in ‘c’ and ‘mmx’ runs much tighter against ‘m’ esp for lower iterates where it is overlapping. ‘m’ max run length variable was renamed here to ‘t’ to avoid the name of the ‘m’ trajectory midpoint variable previously used. the algorithm also found some short ‘c’ cases at low ‘t’ where the prior algorithm flatlines.

(2/16) 😳 😥 😡 @$#& innocently posted the seemingly relatively innocuous/ harmless triangle/ antitriangle ideas on reddit here hoping for the best and maybe some “recognition” and quite to the contrary the crowd was not much impressed “to say the least” (literally?). ok, more candidly, things deteriorated rapidly and some hell broke loose… man! tough crowd! for the trouble got zero vote score and subsequently reported on “bad mathematics” by edderiofer (who so far exhibits no knowledge of the problem whatsoever) and get more upvotes there than on /r/math! anti-algorithmic bias or fractal blindness in the latter? doncha just luv reddit?… whatever! 😐 😦 ![]()
ok, trying to look on that silver lining side (but here also nevertheless it seems a sliver), it wasnt a total fiasco. reddit user sleeps_with_crazy while not very receptive to claims the triangle/ antitriangle fractal images are “never before seen” (like nearly every other redditor in the forum, alas) tipped me off to this great 2013 paper. have always thought that collatz might be simulated on a cellular automaton and looks like someone (Chen) beat me to the proof. it is not so unlikely esp given the (decades-)long known finite state transducer construction. also maybe getting a bit better reception on the much smaller /r/mathpics reddit (full disclosure, posted in maybe a bit )( of desperation). just have to keep my zen attitude together and it sure comes in handy/ is applicable at times like these… 😐
(oh yes not to be overlooked in the melee, here user itoowantone claims to have drawn the same diagram(s) “I was playing with these” 1 decade ago, with other free/ unique philosophy advice worth framing/ savoring for posterity… reminding me of that saying success is the best revenge…) 🙄 😛
youre not special.
this is an idea that occurred to me to try wrt the optimization. there is a sort of “nondeterministic” inverse iteration operation in collatz that some prior code experimented with. the idea is to find “iteration predecessors”. it can be regarded somewhat as a very rudimentary genetic algorithm with a fairly simple 2-valued “mutation” operator. this code uses the same 20 seed init code and then looks for predecessors, and does not do nearly as well as finding long trajectories by a factor of 4 or so (roughly ~200 length trajectories found last experiment, ~50 length in this one, and not different/ smaller right vertical scale 200 vs 400/ 300 previously). however in comparison it does find very-close to maximal run lengths in the trajectories that are found esp in the higher run lengths.

(2/19) 😳 😮 ![]() 😡 👿 😈 😥 🙄 😛 ❗ “YOU GOT THE WRONG GUY!”™ holy @#&% cow what an EPIC drama just got mass harassed/ attacked/ rep mugged/ character assassinated/ vilified by a reddit internet mob! (maybe all those ppl can be nice in some other context…) alas some of my naivete and faith in humans to “reserve judgement/ do the right thing”™ crumbles… was really triggered last few days. head still spinning some )(, still cant keep it all straight, still reeling/ dizzy/ disoriented/ processing… but instead the general theme was lightning flash rush-to-judgement by a few )( then unquestioned by the crowd, and then no possibility of reversal no matter what the counterevidence, ALL DISMISSED as irrelevant… a few thoughts on a post mortem damage assessment control survey of scorched earth conclusion retrospective pov/ commentary…
😡 👿 😈 😥 🙄 😛 ❗ “YOU GOT THE WRONG GUY!”™ holy @#&% cow what an EPIC drama just got mass harassed/ attacked/ rep mugged/ character assassinated/ vilified by a reddit internet mob! (maybe all those ppl can be nice in some other context…) alas some of my naivete and faith in humans to “reserve judgement/ do the right thing”™ crumbles… was really triggered last few days. head still spinning some )(, still cant keep it all straight, still reeling/ dizzy/ disoriented/ processing… but instead the general theme was lightning flash rush-to-judgement by a few )( then unquestioned by the crowd, and then no possibility of reversal no matter what the counterevidence, ALL DISMISSED as irrelevant… a few thoughts on a post mortem damage assessment control survey of scorched earth conclusion retrospective pov/ commentary…
there are comments on my posting on 3 different reddit forums simultaneously. 2 of the posts were by me, and the 3rd was to “badmath” by [x] who clearly now seems to be acting in bad faith. honestly maybe had some trouble keeping track of who was saying what/ where (with not a lot of help from reddits rather unclear-to-disorienting/awkward interface design) and its not a pretty picture in places. anyway looks like all the threads have now finally died out, dust/ ashes settled at smoke cleared and the locusts “attn/ roving blinding tower searchlights” now have moved elsewhere for the moment.
didnt realize was a mod at 1st but it was one of the hi rep (“reddit karma”) mods [x] who 1st “pulled the crank alert” and got backed by a “tag team” effort incl (bad)math mod sleeps_with_crazy mod (what does that MEAN anyway) who supported it/ fueled the fire along with other mods by commenting on the badmath reddit. apparently mostly triggered by claims of novelty of the diagram still standing/ UNREFUTED, YAY! 😎 😀 ❗ + new techniques later in a comment by me mostly buried in the original math thread, thought it was not esp outlandish but apparently on top of the claim of a new diagram, the now-identifiable tipping point/ hair )( trigger/ straw that broke the camels back? 😮 ![]() 😛 😐 😦
😛 😐 😦
“ironically” got quite a few hits from the badmath subreddit where there was “enthusiastic” voting 😐 and very few from the math reddit where it was quickly/ heavily downvoted but apparently got ~30% upvotes. ouch! obviously the crowds are presumably far different and am quite chagrined it looks like maybe few serious mathematicians came from reddit overall, instead probably what might be called just a bunch of crash-scene rubberneckers.
as for the few “mathematicians” that did show up, maybe they didnt see a lot of definitions and notations in the 1st paragraph, maybe saw some ref to code and graphs, more text than formulas, spotted some emoticons, and quickly decided uh huh, yeah, NO MATH HERE!
this all harshly tests that old showbiz saying… or maybe confirms that early darkly-cynical-yet-cuttingly-accurate 20th century quote from a great american philosopher
theres no such thing as bad publicity as long as they spell your name right™
a great many ppl think they are thinking when they are merely rearranging their prejudices™ —Wm James
elsewhere my final msg to badmath, maybe to cf in any future encounter/ ref… pyrrhic victory? ![]()
(2/20) against my better instincts/ buzzing red flag detector/ full blast deafening klaxxon sirens, over presidents day vac (weve had great ones and, “coincidentally” utterly terrible ones) got into extended heavy hours-long distraction/ dialog/ discussion/ debate/ much worse with horrifically aptly named sleeps_with_crazy aka crazymaker. it would take a lot of work to summarize but was a bit aghast at her “sentiments” (to say the least about both sides). from scattered reddit comments, she claims to be a ~40yr old tenure track professor with a Phd (math?) at a research university.
she seems to be the only person on reddit so far encountered (after dodging many poseurs) educated/ qualified to judge significant collatz claims wrt scientific/ math literature. but oh, the horror, as the “dialogue” proceeded, she proceeds to trash my findings/ work/ entire approach/ essential modus operandii/ raison d’etre on nearly )( strongest possible/ conceivable terms whatsoever without even looking at any )( of it asserting theres no point to doing so whatsoever. oh, the excruciating pain, the monumental cyberinjustice.
after decades of cyberwandering/ exploration have nearly )( always felt live and let live™ but here there was a very dark descent into near-madness… staring at the monster/ abyss that stared back™… its like that old saying, trying to remember how this goes exactly… something like if it were only me and her trapped on a desert island (surrounded by hungry sharks!), am sure at least one of us would swim into the ocean… or if one was trapped in a room with sleeps_with_crazy, hitler, and bin laden and a gun with only 2 bullets, the best option would be to shoot her twice 😡 😮 👿 😈
yet, in her passive aggressiveness, broad/ wild “claims” vicious sneers about collatz related work she also managed to dismiss/ disparage much highly established/ historical published work, and she also disparaged/ rejected work in fractals, computational work, etc in such ridiculously/ outlandishly/ cartoonishly/ even childishly prejudiced ways, it bordered on basically a kind of sophisticated/ intellectual willful ignorance/ bigotry! a bizarre combination; man, had to look up that word just to use it correctly. (seems, luckily, rarely run into such ppl these days, 2018.)
am sure such extreme hateful/ egregious comments about “worthless work” that smear/ malign other est scientific efforts would not stand scrutiny long or be tolerated in any respectful/ professional/ elite setting (making her claims of such background increasingly rather dubious, or maybe its her own shadow side/ down-low alter ego in cyberspace!). next day she literally said she was “TUI”, typing under the influence and that it was likely no problem and not atypical among her faculty/ peers…
but and then was not overly surprised to see only ~2 days later another redditor accuse her of (antimale) bigotry in a recent thread that was reading on math, totally accidentally running across her again, ugh. sometimes cyberspace is a small place. holy @#%& howd she get so much reddit karma anyway?!? clearly by being very busy on reddit… dont you have a paper to write or test to grade or student to advise or peer to criticize somewhere else or something? she has defenders in high places… thank some lucky stars she is not reddit mod on math!
may write all this up at some other time, generated copious bookmarks from it all, but right now it still seems more than a bit )( radioactive! not sleeping as well with all the adrenalin rush! anyway this is my final open letter/ response to her, questioning her anti-fractal, anti-applied/ empirical/ and anti-CS drunken-looking slurs. no response in return from the alpha female shadow/ archnemesis/ poison-tongued badmath medusa. halleluja! 😈
honestly, it is just extreme full-contact no-holds-barred sparring practice for the “big time”™.
(2/25) 😳 💡 ❗ 😎 😀 ❤ ❓ these are some new ideas. maybe got a little carried away here but it was rewarded and am very pleased even thrilled with outcome vs effort. this builds on the prior genetic algorithm that was found best at optimizing so far. the basic idea/ theme is to look better at some of the earlier analyzed metrics and how they relate to whether (longest) glides are possible with constraints on those parameters throughout the glide. added some new parameters namely “# of groups of 0, 1” in the iterates. the code has a somewhat obvious optimization not found in prior code. did you spot it? (immed spoiler, lol!) the idea is to terminate the glide immediately if the metric in question exceeds the limit, rather than computing the whole glide and comparing at the end. also, the scaling of all metrics is considered also.
there is also 3 different methods for picking random iterates at the beginning, starting with 200 this time ie 10x more, and the generation code now has similar logic to throw out iterates that fail the threshhold (instead of cleverly constructing them to conform to the prior limited cases). overall this full code while not esp conceptually complex was timeconsuming to get all the iterative logic down, graph the copious data in some not-entirely-visually-overwhelming/ overloading way, and also took awhile just to figure out what ranges to visualize as interesting/ informative/ meaningful.
honestly, not exactly sure what am looking for at moment, but believe there may be or is some striking/ even eyepopping/ breakthru results in here. it will take awhile to summarize all these findings. just wanted to share them immediately without all the analysis to begin with. now really regret not going in this very promising direction sooner! the basic finding is that maybe some or many of these metrics directly measure/ interrelate to/ quantify the “inherent/ fundamental structure”/ self similarity of the fractals in the iterates.
brief/ snapshot hilights: they seem to encode multiple transition point(s) phenomena esp 2nd 2 graphs. there is also some hint that they “encode” a limit on the glide exactly in the long-sought local vs global dichotomy/ relation (esp cf graph 3). and this is possibly an extremely strong advance towards a proof. (the idea that the self similarity measurements leading to/ corresponding to some kind of inductive proof structure is both plausible and very exciting.) another key finding to note is that the 0/ 1 statistics are markedly different here/ asymmetric as has been long noticed somewhat more indistinctly/ vaguely prior to now. fyi the code ran overnight for ~four hours.
btw theres also a very strong connection to/ supporting demonstration of the (information theoretic) entropy… can you guess it? hint: wrt new parameters…




⭐ ⭐ ⭐
💡 ❓ had a few new thoughts on the multidimensional matrix diff eq approach. never did try to figure out how much it outperforms glide prediction length based merely on density. the MDE is all built out of density metrics so that wouldnt be surprising. also the MDE can be used for much more than merely glide prediction, but the basic question still stands. alas, can do a workable job, but linear regression/ statistics is not my long speciality. another idea is that even if the MDE (locally) predicts new metrics more accurately than only using density measurement, what if that still does not significantly improve global prediction accuracy? it pains me to say all this because have many months of investment of work into the MDE approach. but as they say in book/ writing editing “sometimes you have to kill your babies” or something like that…
(2/26) 😳 💡 ❗ ❓ oops the labels are wrong on that 3rd graph, its not the scaled metrics with the ‘s’ suffix but the unscaled ones instead. not too serious and for now am not going to revise it.
pondering the prior graphs led to a big idea. the prior code is looking at longest glides with an upper bound on (“binary” or “bit”) entropy. but how about a lower bound? so here is a basic sketch/ idea/ outline of a proof…!
- trajectories/ glides generally increase the entropy of the iterate as previously observed.
- but maybe theres an “entropy trap” (aka strange attractor with black-hole like attraction) such that after the entropy climbs to a certain level, it does not decrease. ie a sort of one-way phenomenon.
- once inside the “trap” then wondering if the glide length can be bounded.
this would be a phenomenal idea possibly. it splits the proof into two regimes/ phases. the nature of the bounding is much different in each but maybe they can be combined as stated. the 1st regime is more about a monotonic increase in entropy into the “trap” but doesnt directly limit glide length. the 2nd regime is about bounding the glide length based on the entropy trap dynamics.
already an upper-bounded entropy trap wrt glide length is revealed in the prior results. making a lower-bounded one not so outlandish/ implausible. maybe another phase transition? the conjecture seems to imply that extreme entropy lo/ hi leads to trapping whereas intermediate entropy allows longer glides. note these ideas have a lot of strong parallels to the prior density dynamics long explored, aka attractive “density core” region etc. did look for some idea of a “density trap” but was unsuccessful in that (there is the attractive density core but it didnt seem to detectably limit glides much). could this entropy angle be the magic twist? or too good to be true™?

I know it is you…by the way you continue to permit anonymous comments in this age of oppression. Do you remember how the stackexchange guys purged our bitcoin discussion? The vzn of old would have chastised them, he would have crushed them with his morality and eloquence. What has happened to our Hero, the one who was bold enough to take a stand against a whole horde of satan’s minions? If only their nefarious crimes had been exposed on stackexchange, perhaps the public would not have taken such a mighty blow with this bitcoin crash. But I cannot blame you, for perhaps your past work (and trials?) justifies your current impotence. At least you tried – you have done much more than most even attempt.
The Internet has become a monstrosity, a digital Krakow. You tried to save us, but had no support. They craved your identity so they could vilify you, so they could exterminate you. Yes, your enemies would have stooped to such a level, had it been necessary. (You know it, as do I.) But we can see more clearly now, the past and the future are revealed. History will vindicate you, once our collective eyes have had time to recover from the blinding gleam of your sword – the sword which you plunged many a time into the vitals of the dragon! Perhaps that is where you stumbled. Perhaps the caustic gore of that fell beast poured out upon that mighty hand and withered it.
But back to your “post”, your so-called article. Fooey is what I say to your scientific blather! Who can seriously care about such nonsense while the world is being set ablaze, while multitudes of maidens are being gnashed betwixt the teeth of the destroyer? Do you want to manufacture some more technology to feed the beast such that it can oppress us further? Is that a part of some weird deal that you agreed to, in exchange for your life? If you won’t fight, if you won’t re-gird your loins, if you will not scrape the rust off of your armour, then I must ask that you at least cease and desist from this madness. No more technology!! No more! I know, I just know that there is some Amish community nearby that you can join to both cleanse and heal your soul. And if that is too much, if you don’t like horses, for instance, then there are still many other respectable occupations available – woodworking, farming, poetry. I just know you would excel at poetry. I pray that thou will carefully consider these words!
You are right. Fractal entropy proves Collatz conjecture by unlabelled axes.
Pingback: collatz match | Turing Machine
Pingback: collatz outline | Turing Machine